
Apache Sparkは、大規模なデータを扱うためのオープンソースの統合分析エンジンです。
Apache Spark 3.0からはGPUを扱った並列分散処理、3.2ではSpark上でPandas APIの利用が可能となり、2022年6月にはバージョンは3.3になりました。
扱うデータの規模は拡大を続けており、Sparkを利用する機会は益々増えると考えられます。
膨れ上がる大規模データを処理する場合、Sparkの利用は避けて通れず、Sparkの今後の発展にも目が離せません。
- なぜSparkは誕生したか
- Sparkはどのような機能を持つか
目次
Sparkの誕生
Spark誕生のきっかけに、大規模データを分散処理で扱うためのソフトウェアフレームワーク: Apache Hadoopが関わってきます。
Hadoopは、Google File SystemとGoogle MapReduceを参考に2006年にYahoo!から開発され、2008年にApacheトップレベルプロジェクトに昇格したソフトウェア基盤です。しかしながら、Apache Hadoopの大規模データを効率的に分散処理するMapReduceには、処理速度に課題がありました。
そこで、MapReduceの利点を維持しながら、分散処理のパフォーマンスや使いやすさの改善を目的に、2009年にUC BerkeleyのAMPLabのプロジェクトが立ち上がりました。このプロジェクトがSparkの誕生に繋がります。
2010年、Sparkは初めてオープンソースプロジェクトとしてリリースされ、2012年にはインメモリ方式で処理をサポートする分散共有メモリResilient Distributed Dataset: RDDを発表しました。(2)(3)
その後、2013年にApacheのプロジェクトとしてSparkは寄贈され、2014 年にはApacheのトップレベルプロジェクトになりました。
Apache Sparkプロジェクトのコミッターには、DataBricks, Netflix, IBM, Apple, Google, NVIDIA, NTT…etc、数多くの企業からメンバーが名を連ね、現在もプロジェクトのコミュニティ規模は拡大を続けています。(4)
Sparkの特徴

なぜHadoopとSparkの処理に違いが出るのでしょう?
HadoopのMapReduceは、例えば、HDFSのようなディスクへのデータの「read」と「write」をiterationのたびに実行する必要があります。これがプロセス全体の遅延に影響していると指摘されました。
MapReduceを実行するたびにHadoopがディスクへアクセスすることに対し、Sparkは分散共有メモリResilient Distributed Datasets: RDDを利用することで、複数マシンのメモリ(RAM)にデータを分割し、管理します。
RDDは、iterationごとのディスクへの書き込みの省略とRDDからiterationの結果の読み込みをサポートを可能としました。
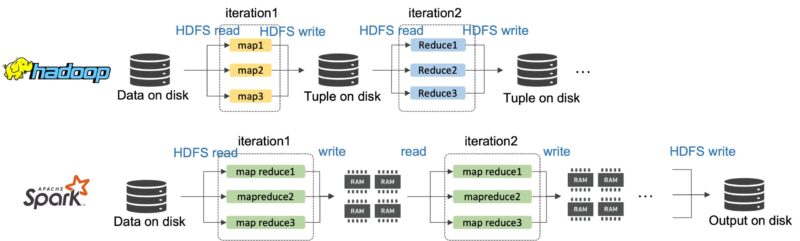
例えば、RAMからの読み込み速度は、ディスクからの読み込み速度の数百〜千倍高速です。インメモリ方式を採用することで、Sparkは大規模データの処理速度をHadoopの10-100倍向上しました。
以下にHadoopとSparkの違いをまとめます。
| Hadoop | Spark | |
|---|---|---|
| 処理速度 | ディスクから読み書きするため、処理速度が低下 | ディスクへの読み書きの頻度を減らし、データをメモリに保存することで処理速度を向上 |
| 利用場面 | バッチプロセスを扱うための設計 | リアルタイムデータを扱うための設計 |
| レイテンシー | 高レイテンシー | 低レイテンシー |
| コスト | コスト面では安価 | インメモリのために多くのRAMを必要とし、高コスト |
| 機械学習 | データのフラグメンテーションは非常に大きいため、処理がSparkより遅い | インメモリとMLlibを使用することで、処理を向上 |
| パフォーマンス | ディスクへの読み書きが都度発生し、パフォーマンスが低い | ディスクへの読み書きを削減し、高いパフォーマンス |
| 言語 | Javaで書かれているが、MapReduceはPythonでも可能 | Scalaで書かれているが、Python, Java, Rでも利用可能 |
| ユーザーフレンドリー | 扱いが難しい | 扱いが楽 |
Sparkのアーキテクチャー

ここではSparkのアーキテクチャーについてまとめます。
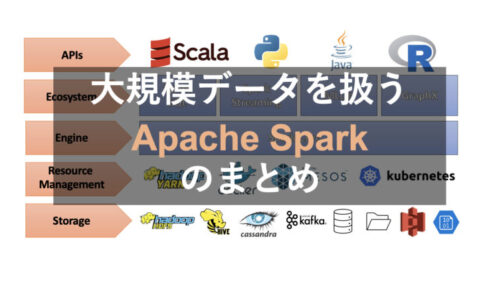
Sparkは、パワフル、かつ、簡単に扱うための5つのコンポーネントから構成されています。
それぞれのコンポーネントは
- ストレージ
- リソースマネジメント
- エンジン
- エコシステム
- APIs
から成ります。
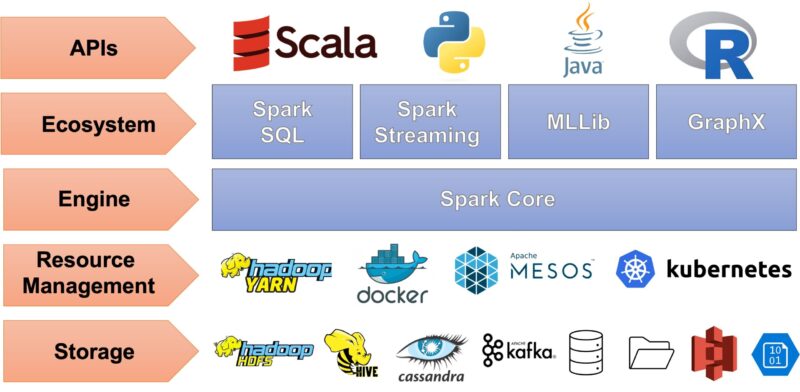
ストレージ
Sparkでデータを処理する前に、データはストレージに蓄積されている必要があります。データは、様々な種類のデータベースに蓄積できます。
Sparkはリレーショナルデータベース(RDB)の利用だけでなく、Cassandra, MongoDBなどのNoSQLの利用も可能です。
リソースマネジメント
Sparkは複数のマシンの集合の上で機能します。複数マシンの集合は「クラスター」と呼ばれます。
あらゆるクラスターには、「リソースマネージャー」があります。リソースマネージャーは、リソース間の作業を効率的に管理します。
代表的なリソースマネージャーには、YARN、Mesosが挙げられます。リソースマネージャーは、「Cluster manager」と「Worker」の2種類のコンポーネントを持ちます。
Cluster managerは、マスターノードとして振る舞います。 例えば、Cluster managerはWorkerに関する以下の情報を管理します。
- Worker noteの状態
- Worker nodeの場所
- Worker nodeのメモリ
- Worker nodeの合計CPUコア数
つまり、Cluster managerの主な役割は、worker nodeを管理し、その情報をもとにそれぞれのworker nodeにタスクを割り振ることです。
一方、worker nodeは、Clsuter managerから与えられたタスクの実行に責任を持ちます。
何だか職場の上司と部下の関係みたいですね。
エンジンとエコシステム
エンジンとエコシステムはRDD(Rssilient Distributed Datasets)の上に立ち、Spark Contributorによって開発されたライブラリやエコシステムを利用するためのAPIを提供します。これがSparkのアーキテクチャーのコアでもあります。
Sparkツールキットはデフォルトで5つのライブラリを提供しています。
- Spark SQL
- MLlib
- Structured Streaming
- Graph X
- Pandas API
Spark SQL
SQLは多くのETLオペレーターに利用されています。 Spark SQLは、SparkユーザーがSQLクエリによって構造化データ処理の実行を可能にします。Spark SQLを利用することで、簡単に多数のデータベースファイルや、SQL、NoSQLのようなストレージシステムを扱えるようになることが利点に挙げられます。
MLlib
SparkのMLlibが登場するまでは、巨大なデータセットに対して機械学習モデルをトレーニングすることは大きなチャレンジになっていました。SparkのクラスターとMLlibの利用は、巨大なデータセットに対して機械学習モデルのトレーニングを可能にします。Spark MLlibでは、教師あり学習、教師なし学習、NLPベースのレコメンダーシステム、ディープラーニングなど、さまざまなモデルの利用が可能です。
Spark Streaming
Spark Streamingは、リアルタイムのストリーミングデータを処理するための機能を提供します。Spark Streamingでは、受信データをバッチデータ、あるいは、異なるソースからの直近のリアルタイムデータとして扱うことができます。構造化ストリーミングは、Flume、Kafka、Twitterなどのソースから得られるリアルタイムデータを取り込み、これをマイクロバッチに変換、その後、Sparkエンジンでこれらを処理します。
Graph X
Graph XはSpark coreの上に立てられ、ユーザーがノードとエッジを含むグラフ構造のデータの処理を可能にします。グラフは異なるオブジェクト同士の関係をモデルするために利用します。ノードはオブジェクトを、エッジはノード同士の関係を表します。グラフデータフレームは主にネットワーク分析で扱われ、Graph Xはグラフデータフレームの分散処理を可能にします。
Pandas API
Apache Spark (PySpark)のPandas APIは、データサイエンティストやデータエンジニアがSparkでpandasを実行することを可能にします。Pandas APIが実装されるSpark 3.2より前は、pandasのDataFrameからPySparkのDataFrameのコードを書く必要があり、時間のコストが大きかったです。また、PySparkでPandas APIを使用したい場合、オープンソースプロジェクトのKoalasを使用する必要がありました。現在、KoalasプロジェクトはSpark 3.2からApache Sparkの一部となり、Pandas APIで気軽にpandasをSpark上で扱えるようになりました。
Programming Language API
Sparkは4種類のプログラミング言語で利用が可能です。SparkはScalaで開発されているため、Scalaがネイティブ言語になります。しかし、Scalaとは別に、Python、Java、RでもSparkは利用できます。
環境構築
Sparkは様々な環境で利用できます。代表的な環境としては、
- ローカル
- Docker
- GCP, AWS, Azureなどのクラウド環境
- Databricks
が挙げられます。
ローカルシステムにSparkをインストールして使用することは比較的簡単ですが、クラスターは使用できません。Sparkの分散コンピューティングは常にローカルシステムからの制約を受けますが、サンプルデータに対してテストコードを書くには良い練習になります。
簡単な流れとしては
- Java Developmetn Kit (JDK)をインストール
- Apache Sparkの最新バージョンをインストール
- zipフォルダからファイルを抽出
- Sparkに関連する全てのファイルを対象ディレクトリにコピー
- Sparkを実行するための環境変数を設定
- Sparkが実行するか確認
になります。
環境構築の詳細な手順は、他サイトかYoutubeを参考にしてください。
まとめ
この記事はSparkの概要についてまとめました。
- Apache Sparkの概要
- 大規模なデータを扱うためのオープンソースの統合分析エンジン
- HadoopのMapReduceの課題解決を目的にUC Berkeleyのチームから開発がスタート
- 現在もプロジェクトのコミュニティ規模は拡大中
- Sparkのアーキテクチャー
- ストレージ、リソースマネジメント、エンジン、エコシステム、APIsから構成
- RDDを利用したインメモリ方式により処理速度を向上
- Scala、Python、R、Javaで利用可能
- Spark SQL、MLlib、Structured Streaming、Graph X、Pandas APIを利用可能
DataBricksの登場で、徐々にSparkは扱いやすくなってきていると思います。Sparkについてはこれからも継続的に学習、スキル習得を目指したいです。
この記事は以上です。最後まで読んで頂きありがとうございました。
参考資料
(1)Apache Spark, Unified engine for large-scale data analytics
(4)Apache Spark, Current Committer
(5)NVIDIA, Optimizing and Improving Spark 3.0 Performance with GPUs
(6) Pramod Singh, Learn PySpark: Build Python-based Machine Learning and Deep Learning Models, 2019
(7) Machine Learning with Spark – Second Edition, 2017








この記事は「Spark誕生の経緯と特徴」をまとめます。