

大学の講義で強烈に印象に残ったタイトルのひとつです。
p値ハッキング: p-hackingは、実際は統計的に差がないデータに差があると示してしまう誤ったデータ分析の行為です。
意識的、無意識的な行為に関わらず、知らないうちにp値ハッキングに手を染めているかもしれないと思うと怖く感じませんか。
p-value

まずp-valueってどんなものでしたっけ?
p-valueは観測結果に基づいて差異の有無を判断するための確率です。
観測結果の差異がサンプリングエラー、または、偶然発生したものか確認するため、多くの分析者が、t検定、F-検定、Z-検定、カイ二乗検定、などの有意差検定: significant testを実施します。
もしp-valueが十分に小さければ(0.05以下であれば)、2つ以上の母集団に差がないと仮定する帰無仮説: Null hypothesisを棄却し、観測結果に統計的な差があると捉えます。
p値ハッキングとは
一方、p値ハッキングは、統計的有意でないデータを有意と示してしまう誤ったデータ分析の行為です。
p値ハッキングは、データ・スヌーピング: data snooping, データ・ドレッジング: data dredging, データ・フィッシング: data fishingとも呼ばれます。(1)
具体的にどんな行為がp値ハッキングに繋がるんでしょうか?
xkcdの「ジェリービーンズの摂取がニキビの原因」で、p値ハッキングの一例があげられます。

このストーリーは
- ジェリービーンズを食べることがニキビの原因であるという仮説を立て、検定を実施した。
- 検定の結果はp>0.05、ジェリービーンズを食べることはニキビの原因と関係ないと示唆された。
- ある色のジェリービーンズを食べることはニキビの原因になるという新たな仮説を立て、20色のジェリービーンズを使って検定した。
- 検定の結果、緑色のジェリービーンズはp<0.05だった。緑色のジェリービーンズを食べることがニキビの原因になると示唆され、これがニュースとして報じられた。
という内容です。

検定の過程がp値ハッキングにあたります。
まず、1回目の検定では、ジェリービーンズの摂取はニキビの原因に関係しないことが示唆されました。
しかし、2回目の検定では、緑色のジェリービーンズの接種がニキビの原因に関係すると示唆されています。
なぜ2回目のような検定結果が出たのでしょう?
同じデータで何度も検定を繰り返すと、帰無仮説を誤って棄却する確率が高まるからです。
帰無仮説が正しい場合、p-valueは一様分布: Uniform distributionを取ります。つまり、2つ以上の母集団に差がないと仮定する帰無仮説が真の場合でも、5%の確率で誤って帰無仮説を棄却する可能性があります。(TypeⅠErrorとも呼ぶ)
20種類準備したジェリービーンズのうちの少なくとも1つの色が効果があると誤って判断してしまう確率は
$$1-0.95^{20}\approx 0.64$$
となります。
これは、同じデータで何度も検定を繰り返すと、TypeⅠErrorが起こる確率が5%から64%に上がってしまうことを意味します。
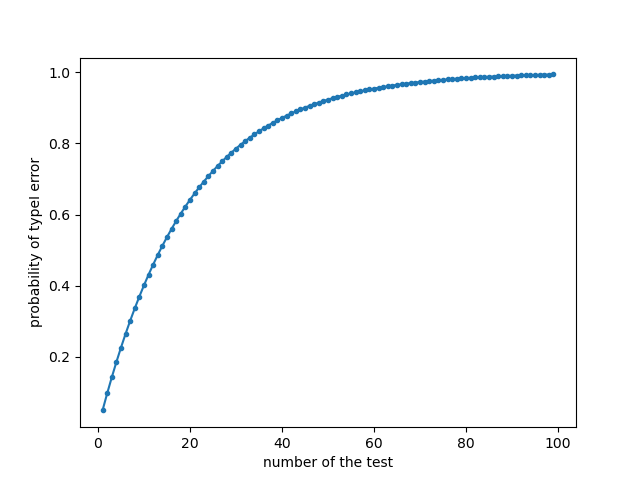
何度も検定を繰り返せば、有意差って出やすくなるものだったんですね。
以下はジェリービーンズが誤って帰無仮説を棄却してしまうことを確認するためのpythonのコードになります。
データセットは、ニキビの状態、ジェリービーンズの接種状況、食べたジェリービーンズの色を、独立同一分布で生成します。
「ジェリービーンズの摂取とニキビの状態」に有意な差はありませんでした。

ニキビとジェリービーンズの色は互いに独立の関係ですが、「青緑色のジェリービーンズの摂取とニキビの状態」に有意な差が確認されました。
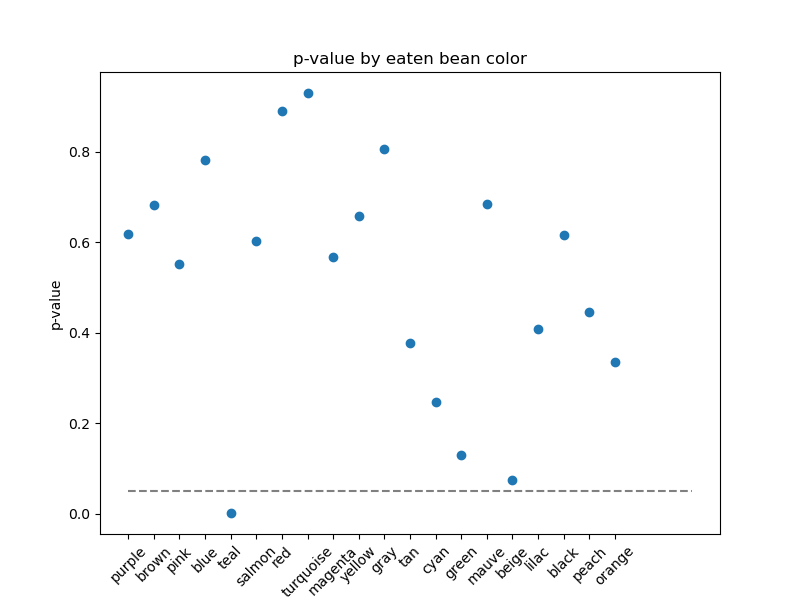
p値ハッキングの原因
p値ハッキングで最も問題となる行為は、データ取得後、あるいは、検定結果を確認した後に以下の行為に及ぶことです。
- 新たなデータを取得・追加した
- 外れ値と判断し、いくつかの測定値を除外した
- 効果に寄与すると思われる測定値を選択的に抽出した
- 別の方法でデータ分析を実施し、検定に微調整を加えた
なるほど。では、どうしたらp値ハッキングを防げるんでしょう?
p値ハッキングを防ぐ
If you torture data long enough, it will confess to anything.
Ronald Coase
「都合いいように時間をかけてデータをいじれば、データは我々が望む答えを何でもはき出す」
この言葉は、データ分析が必ずしも客観的な分析ではないことに警鐘を鳴らすノーベル経済学賞受賞者のRonald Coaseのメッセージです。

近年、学術・ビジネスにおいて、p-valueの誤用、誤解が問題視されており、物事の本質を追求するための研究、データ分析のあり方が問われています。(4)
p-valueの誤用を防ぐため、以下の案が提案されています。
- 実証分析の厳密性・妥当性を高めるため、事前に研究計画を登録する
- p < 0.05といった基準に過度にとらわれない
- p値の関連した解析結果を選択的に報告しない
- 透明性を高めるため、データの結果を素直に報告する
公正な研究を保障するため、私たちは目先の結果に囚われ、データを操作するよう誘惑されてはいけないということですね。
まとめ
この記事はp-hackingについてまとめました。
- p値ハッキング
- 統計的有意でないデータを有意と示してしまう誤ったデータ分析の行為
- 別名: データ・スヌーピング、データ・ドレッジング、データ・フィッシング
- p値ハッキングの原因
- データ取得後、あるいは、検定結果を確認した後に
- 新たなデータを取得・追加
- 外れ値と判断し、いくつかの測定値を除外
- 効果に寄与すると思われる測定値を選択的に抽出
- 別の方法でデータ分析を実施し、検定に微調整を実施
- データ取得後、あるいは、検定結果を確認した後に
- p値ハッキングの防止策
- 実証分析の厳密性・妥当性を高めるため、事前に研究計画を登録する
- p < 0.05といった基準に過度にとらわれない
- p値の関連した解析結果を選択的に報告しない
- 透明性を高めるため、データの結果を素直に報告する
今まで以上に多くの人がデータ分析に関わる時代、誤った結論に至らないためにも、p値は適切に理解しないといけないんですね!
この記事は以上になります。最後まで読んでいただきありがとうございました。
参考資料
(1) Stanford Data Science, Data Snooping, January 7 2022
(2) explain xkcd, 882: Significance(2022/7/17アクセス)
(3) Digital Business & Business Analytics, Analytics Cartoon(2022/7/17アクセス)
(4)日本計量生物学会, 統計的有意性とP値に関するASA声明, 2017.4.23
(5) Statistical Significance, p-Values, and the Reporting of Uncertainty(2022/7/16 アクセス)
(7) エゴナ学術英語アカデミー、P値に関する問題-P値ハッキング(2022/7/19アクセス)









p値ハッキングを自分の中でもう一度整理するため、この記事は「p値ハッキング」についてまとめます。