
ETL、ELTはデータの処理プロセスに関する用語です。
行政、産業、科学、医療、 etc.、あらゆる分野において、ビッグデータの活用が注目されています。
しかし、データソースから得られたデータを分析用データと統合する前に、データ変換を実施する必要があります。これは、多くのケースで、(1)データソースごとでデータスキーマが異なる、(2)登録者・部署ごとのデータ登録・管理・運用方法が異なる、ためです。
このような不一致、かつ、膨大なデータの管理作業は面倒な手間と時間がかかるうえ、専門の知識・スキルが必要となります。
これを解決すべく、ETL、ELTは、データ処理・管理の効率を高めるためのサポートを目的に開発されました。
- ETLとは何か
- ELTとは何か
- それぞれのメリット・デメリットは何か
目次
言葉の定義

ETLとELTの話の前に、おさえておきたい定義です。
- 抽出(Extract): オリジナルのデータソースやデータベースから、必要なソースデータを取得するプロセス。
- 変換(Transform):情報の構造を変更するプロセス。e.g. 平均、削除、匿名化、etc…
- 格納(Load):情報をデータストレージシステムに格納するプロセス。
データソース(Data source)は、使用するデータの源泉です。「データが最初に作成される場所」「物理データが最初にデジタル化される場所」を指します。RDBMS、ストリーミングデータ、センサによる計測データなど、外部ですでに精緻化されているデータをデータソースとみなす場合もあります。(1)
データストレージ(Data storage)は、データをアーカイブ、整理、共有するための補助記憶装置です。ストレージデバイスは、パンチカードから始まり、磁気テープドライブ、フロッピーディスク、ハードディスクドライブ、コンパクトディスク、フラッシュメモリ、と容量・携帯性を向上してきました。(2)
近年は、インターネットを介して、データの保管・共有を行うオンラインストレージ(Online storage)が普及しています。オンラインストレージはクラウドストレージとも呼ばれます。
データストレージ・システム(Data storage system)は、データソース、データストレージ、それらを繋ぐネットワークを含めたシステム全体のことを指します。
ETLとELT
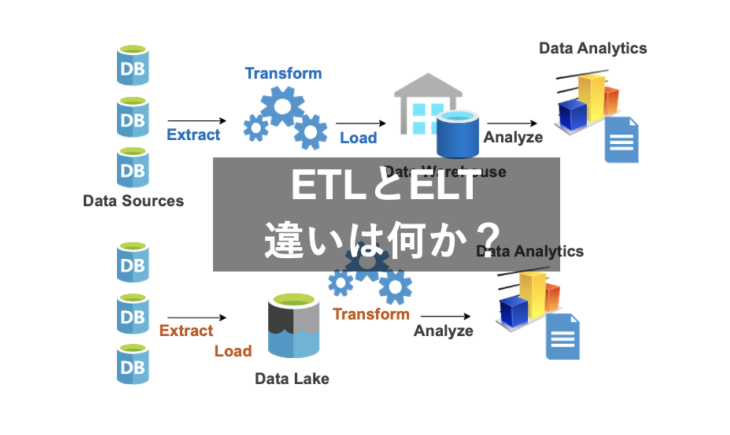
結論から言うと、ETLとELTの違いは「データ変換をどのタイミングで行うか」です。
ETL
ETLの特徴

ETLはどんなプロセスですか?
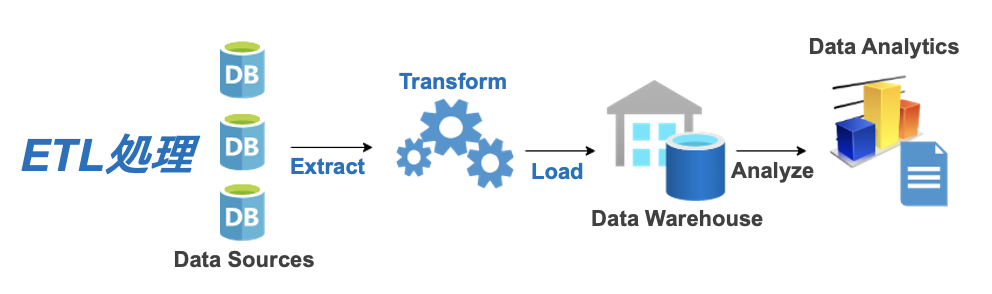
ETLのプロセスは「Extract(抽出)- Transform(変換)- Load(格納)」です。データ変換は、データストレージへデータを格納する前に行われます。
オンプレミス、クラウドに関係なく、ETLの代表的なデータストレージにデータウェアハウス(Data warehouse: DWH)があげられます。そのため、データストレージには構造化データが格納されます。
ETLに関するツールは、1990年代から20年以上にわたって開発・使用されており、Xplenty、AWS Glue、など、ETLを行うための強力なツールが提供されています。
ETLのメリット
- 効率的でスピーディーなデータ分析
- プライバシーの保護
- コンプライアンスの遵守
- ETLの知識・スキルを持つ専門家が多い
変換済みの構造化データがデータウェアハウスに格納されています。したがって、データ分析の際、データアナリストの作業は、データウェアハウスから必要なデータを取り出すだけとなります。
また、データストレージ格納前にデータ変換を行うということは、分析用データへの統合前に不必要なデータを除去、データを匿名化が可能であることを意味します。これはプライバシー保護に繋がります。
データ管理に関しては、国ごとで規制内容が異なり、何でもかんでもデータを登録・持ち出すことができません。ETLは、コンプライアンス違反のリスクも低減します。
データウェアハウスは、加工したデータが綺麗に仕分けされている巨大な倉庫のイメージです。

ETLのデメリット
- リアルタイムのデータ分析に課題
- データ活用の範囲を限定
ETLは、データウェアハウスへデータを格納するまでに多段階のプロセスを経るため、データ格納までの処理時間が長くなります。
また、構造化されたデータが、新しいタイプのデータ分析の実施を妨げる場合があります。その場合、1)ETLのデータパイプライン全体、2)データウェアハウスのデータ構造、を見直す必要が生じます。
ELT
ELTの特徴
ETLに対して、ELTはどんなプロセスなのでしょう?
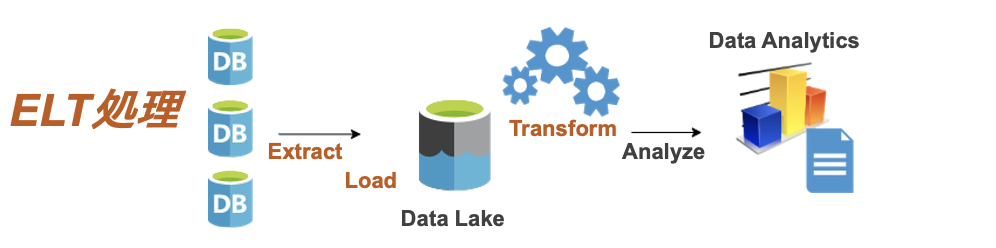
ELTのプロセスは「Extract(抽出)- Load(格納)- Transform(変換)」です。
そのため、構造化データ、非構造化データ、半構造化データ、ローデータ、といったあらゆる種類の”未加工”データがデータストレージに格納されます。変換はデータストレージにデータを格納した後で行います。
ELTの代表的なデータストレージには、データ形式に関係なく、未加工データを保存できるデータレイク(Data lake)を利用します。
ELTのコンセプト自体は新しいものではありませんが、比較的新しいテクノロジーです。Apach Hadoopのようなツールの登場、クラウドベースのテクノロジー進化によって、コンセプトの実現を可能とし、2010年代から再び注目を集め始めました。(4)
ELTのメリット
- あらゆる種類のデータを処理
- データストレージにデータを高速で格納
- データ活用の柔軟性を向上
ELTは変換を行わず、あらゆる種類のデータをデータレイクに格納します。そのため、膨大な量のデータの迅速な処理が可能です。
また、未加工のあらゆるデータにアクセスできる状態となっているため、ETLに比べて、より柔軟なデータ分析が可能となります。
ELTのデメリット
- 機密情報漏洩のリスク
- コンプライアンス違反のリスク
- 技術が発展途上
- ELTの知識・スキルを持つ専門家が少ない
未加工データですから、ハッキングや不注意によって重大な情報の漏洩リスクがあります。クラウドサーバーが他国にある場合、コンプライアンス基準に違反する可能性もあります。
さらに、ELTは発展途上中ということもあり、現状、優れた知識・スキルを持つ人材を見つけることが難しいです。
まとめ
ETLとELTの違いをまとめます。
- ETL
- Extract(抽出) – Transform(変換) – Load(格納)
- データウェアハウスに構造化データを格納
- 効率的・高速なデータ分析
- 情報漏洩・コンプライアンスのリスクに強い
- データ活用の範囲を限定
- ELT
- Extract(抽出) – Load(格納) – Transform(変換)
- データレイクにあらゆるデータ形式のデータを格納
- 高速なデータ処理
- データ活用の範囲を拡大
- 情報漏洩・コンプライアンスのリスクに弱い
- 発展途上の技術で専門家は少ない
ETL、ELTのどちらが良く、どちらが悪いとは言えません。データ分析の目的、データ処理の負荷、を考慮して、データパイプラインを設計・設置する必要があるからです。
参考資料
(1): talend, “what is data source?” (7/7/2021アクセス)
(2): Red Hat, “データストレージデバイスの簡単な歴史” (7/7/2021アクセス)
(3): Mark Smallcombe, Xplenty, “ETL vs ELT: 5 Critical Differences”, March 16, 2021
(4): Prabodh Mhalgi, LinkedIn, “Traditional ETL vs ELT on Hadoop”, April 12, 2017








この記事は「ETLとELTの違い」をまとめます。