
大規模データの分析を強力にサポート: Apache Sparkの概要
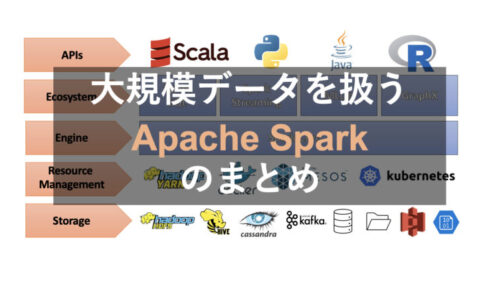
Apache Sparkは、大規模なデータを扱うためのオープンソースの統合分析エンジンです。 Apache Spark 3.0からはGPUを扱った並列分散処理、3.2ではSpark上でPandas APIの利用が可能とな...
 データベース
データベースApache Sparkは、大規模なデータを扱うためのオープンソースの統合分析エンジンです。 Apache Spark 3.0からはGPUを扱った並列分散処理、3.2ではSpark上でPandas APIの利用が可能とな...
 機械学習・最適化
機械学習・最適化クラスタリング(またはクラスター分析)は、集合に含まれるオブジェクトの類似度に基づき、それぞれのオブジェクトをグループ分けする手法です。 クラスタリングは、例えば、機械学習、パターン認識、画像分析、情報検索、バイオインフ...
 データベース
データベースETL、ELTはデータの処理プロセスに関する用語です。 行政、産業、科学、医療、 etc.、あらゆる分野において、ビッグデータの活用が注目されています。 しかし、データソースから得られたデータを分析用データと統合する前に...
 その他
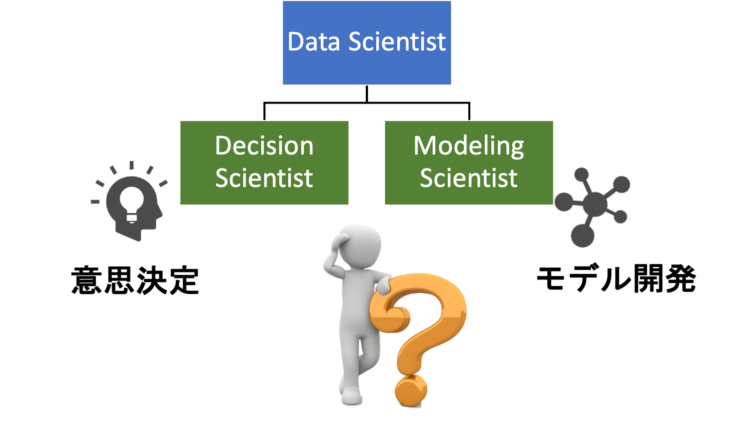
その他マーケティング、経営、人工知能(AI)、医療、生産、物流、工学など、様々な分野でデータサイエンスの活用が期待されています。 しかし、これだけデータサイエンスの活用の範囲が広いと、データサイエンティストがまるでスーパーマン...
 その他
その他データサイエンティストとして働くためにプログラミング言語の習得は必須です。 とはいいましても、どのプログラミング言語を勉強したらいいか分からないですよね。 この記事では管理人が「大学のデータサイエンスコースで学んだプログ...
 その他
その他この記事はデータサイエンスについて紹介します。データから意味のあるインサイトを見つけ出すことを目的に、⑴ドメイン知識、⑵コンピュータサイエンス、⑶数学・統計、が融合した分野をデータサイエンスと言います。

